Estimated read time: 2 minutes
My social media footprint is not huge. But to get some of that delightful dopamine, I post pictures of my Honda Monkey to strangers instead of bothering my closets friends. For this I use a small Instagram account called @monkey_tripper.
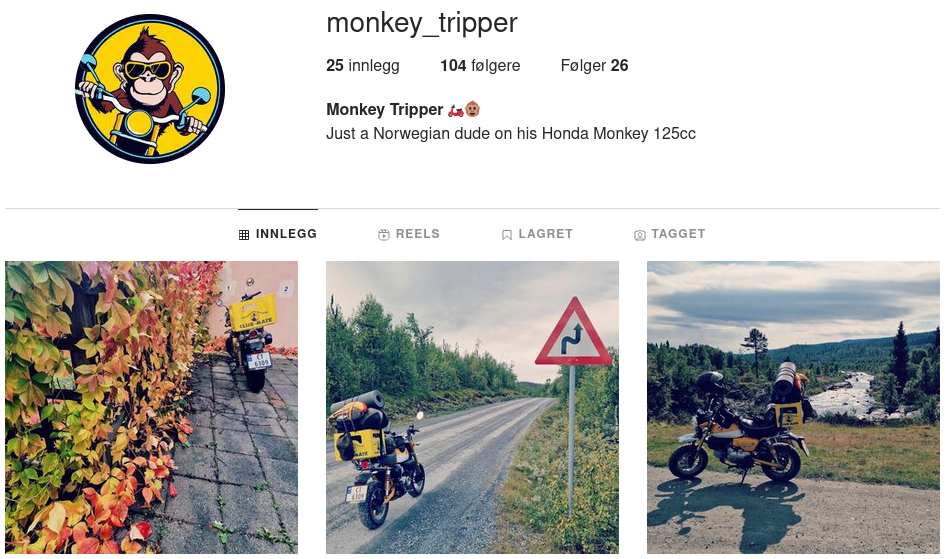
Inspired by this article, I figured I could generate …

